01 June 2024, Saturday
GPT-2 parallelisation (part 1): token embedding and positional encoding with CUDA
In GPT-2 parallelisation: embedding with SIMD (part 1), we showed SIMD parallelisation of token embedding and positional encoding on CPU. We showed that SIMD and multi-threading using OpenMP allowed us to gain a speedup of around 20 (i.e., 20 times faster).
In this article, we attempt to do similar parallelisation, however, this time we shall use a GPU with CUDA.
One could argue that we are trying to optimise the wrong thing here, since a large portion of the computational effort is spent on the QKV and attention calculations, for instance? This is true; however, we want to first understand the parallelisation strategies and their impact on performance using a simple algorithm, that which contains computational patterns that we are likely to find in the more complicated and time consuming portions of the Transformer.
In other words, we should first understand the simple clearly, before we tackle the complicated.
As we shall soon see, the GPU parallelisation presents various possible strategies which affect how the code performs, depending on the hardware characteristics. Unlike SIMD and OpenMP parallelisation, it is important to understand a bit more in detail what the GPU hardware is offering. It takes exploiting a lot more computational parameters and hardware specifics to draw the best performance.
We know that GPT-2 (small) model uses C = 768 hidden channels, which is 32 × 24. Since each CUDA warp consists of 32 threads, this means that we will need 24 warps to process the embedding for a token. A warp is the scheduling unit, which is how thread blocks are scheduled to one of the streaming multiprocessors (SM) on the GPU.
We can summarise this parallelisation strategy with the following diagram.
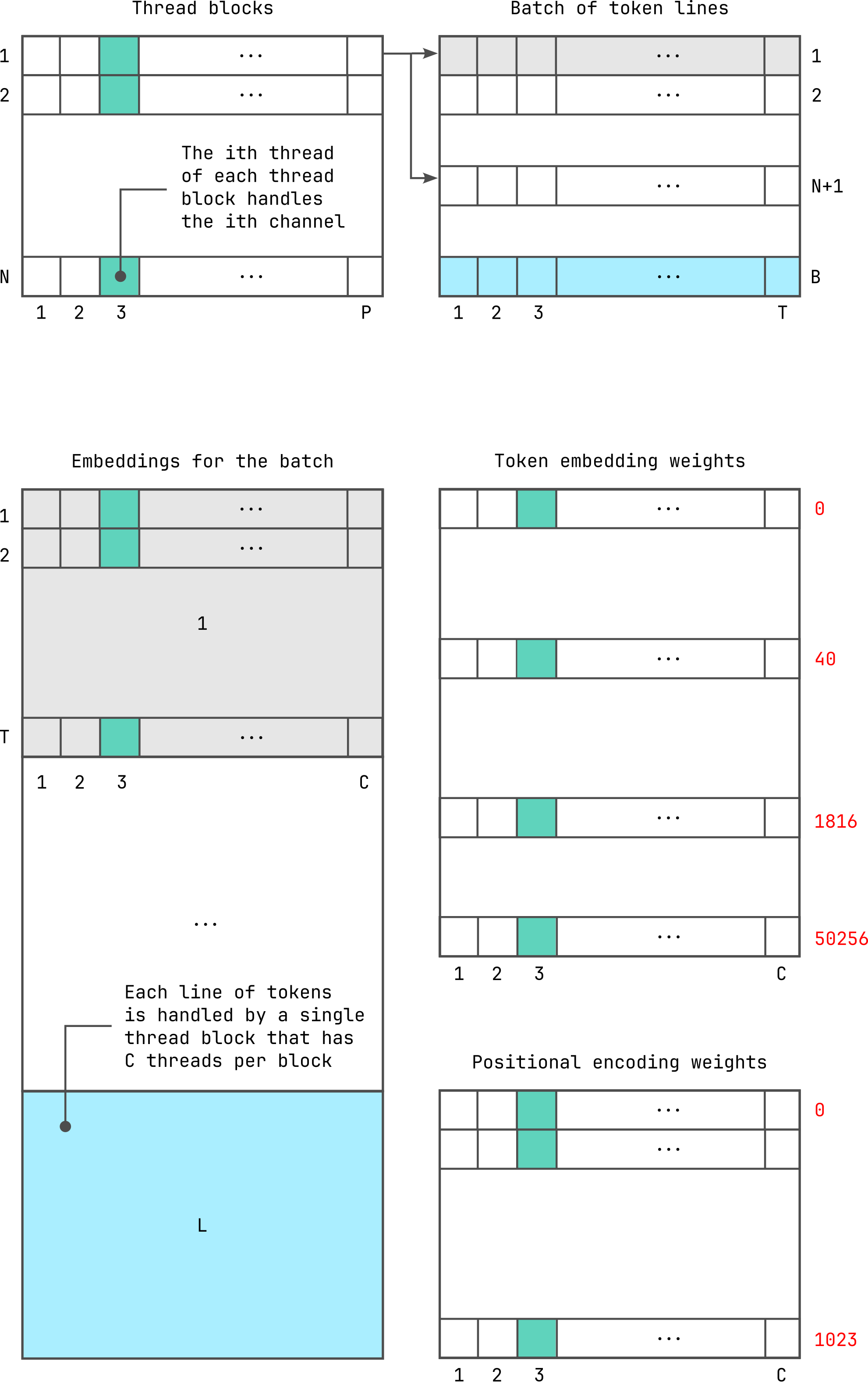
Here, B is the batch size, which is the number of token lines to process with each kernel launch, with each token line consisting of T = 1024 tokens. When we parallelise using CUDA, N here gives the number of thread blocks in the grid when the CUDA kernel is launched, with each thread block consisting of P threads per block. We launch this kernel for each batch of token lines, and continue until all of the token lines have been processed. In our current implementation, each thread in the thread block is made to handle a channel, which means that P = C = 768 threads per thread block.
Each token line is processed by a thread block, such that all of the
thread blocks in the grid process multiple token lines simultaneously,
depending on the available SMs. When the number of thread blocks N in the grid are fewer than the
number of token lines in the batch B, each thread block will process
more than one line of tokens. For instance, in the diagram, the first
thread block is processing token lines 1 and (N+1) in the batch. Finally, to
complete a token line with T = 1024 tokens per line, each
thread needs to iterate 1024 times adjusting the addresses for each
iteration inside embedding, wte and
wpe.
This parallelisation strategy simplifies the implementation, however, we will see later that reducing the number of threads per block can help increase occupancy. The more active warps scheduled to all of the available SMs, the higher the thread occupancy on the SMs, which means better throughput.
The CUDA kernel for a straightforward implementation of this strategy is as follows:
__global__
void embed_tokens_cuda_v1(
float * __restrict__ embedding,
const uint32_t * __restrict__ tokens,
const float * __restrict__ wte,
const float * __restrict__ wpe,
uint32_t batch_size, // Token lines per batch (B in diagram)
uint32_t tokens_per_line, // Tokens per line (T in diagram)
uint32_t num_channels // Number of hidden channels (C in diagram)
)
{
const int block_id = blockIdx.x;
const int thread_id = threadIdx.x; // Thread ID within block
const int num_blocks = gridDim.x; // Number of thread blocks (N in diagram)
// Points to the start of the tokens for the current line for block
const uint32_t *line_start_ptr = tokens + block_id * tokens_per_line;
// When we are done processing the current line, how far should we jump
// to get to the start of the the next line of tokens for this block
const size_t inc_next_line = tokens_per_line * num_blocks;
// How many channels does a line of tokens generate
const size_t channels_per_line = tokens_per_line * num_channels;
// Where is the start of the embedding buffer where we need to write
// the embedding for current thread within the current block
float *e_ptr = embedding + block_id * channels_per_line + thread_id;
// When we are done processing the current line, how far should we jump
// to get to the start of the embedding buffer for the next line of
// tokens for this thread in this block. Notice that we need to use this,
// we are already at the channel for the last token in the current line
const size_t inc_embedding_next_line = channels_per_line * (num_blocks - 1);
// Offset from wte pointer for this thread, since, no matter the token
// chosen, this thread must always access the same channel in the weights
const float *thread_wte_ptr = wte + thread_id;
for (int line = block_id; line < batch_size; line += num_blocks) {
const float *p_ptr = wpe + thread_id;
for (int t = 0; t < tokens_per_line; ++t) {
uint32_t token = line_start_ptr[t];
const float *t_ptr = thread_wte_ptr + token * num_channels;
// Memory access coalesced: all threads access contiguous
// global memory, reducing number of memory transactions
__syncthreads();
*e_ptr = *t_ptr + *p_ptr;
e_ptr += num_channels;
p_ptr += num_channels;
}
line_start_ptr += inc_next_line;
e_ptr += inc_embedding_next_line;
}
}One key characteristic of this parallelisation strategy is that all of the memory accesses to generate the embedding are coalesced (see line 50), since all of the threads in a half-warp will be accessing contiguous memory locations. This is important for improving memory access throughput.
Notice, however, that all of the global memory accesses to get the
token value token (see line 44) could
be optimised. At the moment, in each iteration, all threads are
accessing the same token value from global memory. Of course, this value
will be accessed using a memory transaction and broadcast to the
threads, however, we still need T memory transactions to
load the T tokens in a line (unless the CUDA compiler knows
how to optimise this automatically). Instead, if we make each thread in
a block load a token value into shared memory, and make those
accesses contiguous, we will reduce the number of global memory accesses
to retrieve the token values, because these will also be coalesced to
fewer memory transactions.
Another area for improvement is the occupancy.
Within each thread block, each thread will process one channel of the
embedding. This means that the i-th thread will access only the
i-th channel in the
embedding buffer (the result), and also the token embedding
(wte) and positional encoding (wpe) weights.
This is highlighted in green, for the 3rd thread/channel. Furthermore,
after every 24 warps in each thread block, one token embedding will be
completed. This suggests that we could improve the current
implementation by increasing the occupany, which can be done by reducing
the number of threads to allow the 24 warps to exists simultaneously,
i.e., reduce P to increase the
number of thread blocks N so
that more thread blocks can exists in the available SMs. Remember that
all warps for a given thread block must be scheduled on the same SM
where the thread block is scheduled.
To pre-load a line of tokens to shared memory, which is shared by all of the threads in the thread block, we add the following at line 15:
const int num_threads = blockDim.x;
// Shared memory to pre-load tokens for a line
// Allocated dynamically during kernel invocation
extern __shared__ uint32_t line_of_tokens[];This allocates a shared memory that has room to store a line of tokens, which is 1024 tokens. The actual allocation of the shared memory is done when the kernel is invoked, as follows:
embed_tokens_cuda_v2<<<
num_thread_blocks,
num_threads_per_block,
model->max_token_length * sizeof(uint32_t) // Shared memory
>>>(
model->d_embedding, model->d_tokens,
model->d_wte, model->d_wpe, batch_size,
model->max_token_length, model->num_channels
);To actually load the tokens, we insert the following just above line 41:
// Pre-load a line of tokens into shared memory to allow
// memory coalescing of token reads from global memory
__syncthreads();
for (int t = thread_id; t < tokens_per_line; t += num_threads)
line_of_tokens[t] = line_start_ptr[t];
__syncthreads();and replace line 44 with:
uint32_t token = line_of_tokens[t];To produce:
__global__
void embed_tokens_cuda_v2(
float * __restrict__ embedding,
const uint32_t * __restrict__ tokens,
const float * __restrict__ wte,
const float * __restrict__ wpe,
uint32_t batch_size, // Token lines per batch (B in diagram)
uint32_t tokens_per_line, // Tokens per line (T in diagram)
uint32_t num_channels // Number of hidden channels (C in diagram)
)
{
const int block_id = blockIdx.x;
const int thread_id = threadIdx.x; // Thread ID within block
const int num_blocks = gridDim.x; // Number of thread blocks (N in diagram)
const int num_threads = blockDim.x; // Number threads per block (P in diagram)
// Shared memory to pre-load tokens for a line
// Allocated dynamically during kernel invocation
extern __shared__ uint32_t line_of_tokens[];
// Points to the start of the tokens for the current line for block
const uint32_t *line_start_ptr = tokens + block_id * tokens_per_line;
// When we are done processing the current line, how far should we jump
// to get to the start of the the next line of tokens for this block
const size_t inc_next_line = tokens_per_line * num_blocks;
// How many channels does a line of tokens generate
const size_t channels_per_line = tokens_per_line * num_channels;
// Where is the start of the embedding buffer where we need to write
// the embedding for current thread within the current block
float *e_ptr = embedding + block_id * channels_per_line + thread_id;
// When we are done processing the current line, how far should we jump
// to get to the start of the embedding buffer for the next line of
// tokens for this thread in this block. Notice that we need to use this,
// we are already at the channel for the last token in the current line
const size_t inc_embedding_next_line = channels_per_line * (num_blocks - 1);
// Offset from wte pointer for this thread, since, no matter the token
// chosen, this thread must always access the same channel in the weights
const float *thread_wte_ptr = wte + thread_id;
for (int line = block_id; line < batch_size; line += num_blocks) {
// Pre-load a line of tokens into shared memory to allow
// memory coalescing of token reads from global memory
__syncthreads();
for (int t = thread_id; t < tokens_per_line; t += num_threads)
line_of_tokens[t] = line_start_ptr[t];
__syncthreads();
const float *p_ptr = wpe + thread_id;
for (int t = 0; t < tokens_per_line; ++t) {
uint32_t token = line_of_tokens[t];
const float *t_ptr = thread_wte_ptr + token * num_channels;
// Memory access coalesced: all threads access contiguous
// global memory, reducing number of memory transactions
__syncthreads();
*e_ptr = *t_ptr + *p_ptr;
e_ptr += num_channels;
p_ptr += num_channels;
}
line_start_ptr += inc_next_line;
e_ptr += inc_embedding_next_line;
}
}While the above was required for older GPUs, newer GPUs may not require this. This is because we are accessing the tokens consecutively in each thread block, and newer GPUs will automatically load a cache line into the L1 cache. In fact, the above is likely to introduce overheads as we have to handle shared memory explicitly, and redoing what the hardware has already done. From Maximize Memory Throughput:
“For some applications (for example, for which global memory access patterns are data-dependent), a traditional hardware-managed cache is more appropriate to exploit data locality. As mentioned in Compute Capability 7.x, Compute Capability 8.x and Compute Capability 9.0, for devices of compute capability 7.x, 8.x and 9.0, the same on-chip memory is used for both L1 and shared memory, and how much of it is dedicated to L1 versus shared memory is configurable for each kernel call.”
As described in Device Memory Accesses, each thread in a warp can access words of width 1, 2, 4, 8, or 16 bytes. Hence, if all memory accesses are coalesced and addresses of the global memory are aligned for the word width, each warp can issue a single memory access transaction of 32, 64, 128, 256, or 512 bytes to serve all of the access requests from the threads in the warp.
In our example, since each token, the corresponding weights and the final embedding are all 4 bytes wide (32-bit unsigned integer for tokens, and 32-bit single-precision floating point values for the weights and embedding), each coalesced access for a warp can be served with a single 128 byte wide memory transaction. Furthermore, since this is cached in the L1 cache, the above pre-loading of tokens is unnecessary in this case.
We will use the NVidia NSight System and Compute to carry out performance analysis of the above implementation, and try to analyse and optimise further in subsequent articles. We have decided to separate this because the NSight tools offer a comprehensive analysis of the kernel and overall system performance, and putting the content here will make this article a bit too long.
